软件介绍
该扩展目前是基于Chrome浏览器,如果你正在使用该浏览器可以继续往下看,如果没有可以在你浏览器的扩展商店里面搜索一下标题名称,看看是否存在之后再决定是否查看文章内容,时间宝贵。
该扩展目前的功能相比传统的数据抓取软件肯定是差了很多的,但是其操作简便程度以及对于数据的获取方式非常适合新手,你只需要点击几个按钮基本就可以获取当前页面你需要抓取的数据。
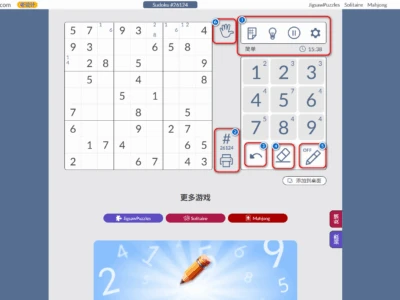
下图是我基于之前推荐的项目配合上当前扩展的一个效果截图:

安装扩展的过程这里就不细说了,如果不会安装可以在文末看看推荐的安装教程。上图中一共存在7️⃣个按钮,当你在一个页面点击扩展栏图标之后,就可以可以看到上面的界面了。
1️⃣号按钮是切换数据获取的区域,以上图为例,当前获取的数据就是7️⃣号界面,对应的是左边红框内的数据,如果你点了1️⃣号按钮,就会切换到下面绿色背景的区域。
2️⃣号按钮是确定「下一页」按钮的位置,因为有些数据涉及到了翻页的过程,而你需要操作的就是点击2️⃣号按钮之后,找到页面的下一页按钮点击即可。如果需要采集的数据页面使用的是瀑布流或者通过ajax动态加载的页面,可以直接勾选4️⃣号按钮,此处按钮就直接忽略即可。
3️⃣号按钮就是开始抓取,点击按钮之后扩展会开始自动翻页抓取所有的数据。
4️⃣号按钮针对的是一些瀑布流或者需要往下滚动才会加载数据的那种页面,选择性勾选。
5️⃣号按钮则为数据的导出和复制操作,这里就没什么必要细说了,操作一下就明白了。
6️⃣号按钮处显示了所有的相关数据,包括页数、采集的数据量、每页数据量以及运行时间
7️⃣号区域则为数据的区域,你可以通过红色箭头处的❌按钮来删除当前列,留下你需要的数据。
整体的使用看上去比较复杂,其实使用一次,你就了解了,非常明白且简单。需要说明一下,如果你想要通过该扩展采集某些站点的数据是不推荐的,无论是法规还是效率来说,都是不推荐的,扩展的意义仅在于小范围的提取数据用作处理。
额外补充
有些站点针对数据采集做了一定程度的限制,比如一定时间内的访问频率,该扩展默认情况下的延迟是1秒,你可以通过修改「Min delay」的数值来修改延迟秒数,自行测试得出一个合理且效率的值。
最后强调一下,扩展的目的是提取数据,而不是采集数据,请各位用之前衡量相关利弊。
如果你不会安装扩展,可以看看下面的文章: